
| ||
| auteur : Jean-Marc Rabilloud | ||
Pour bien comprendre cette différence il faut appréhender correctement comment fonctionne la logique de mise à jour dans un contexte déconnecté. Je vais prendre comme exemple le DataAdapter, mais le fonctionnement général reste le même quelle que soit la technique de mises à jour.
Pour pouvoir envoyer les mises à jour vers le SGBD, le DataAdapter va parcourir la collection des lignes modifiées de la table et appliquée la commande correspondante. Le DataAdapter contient trois commandes d'action (Update, Insert et Delete). Chaque ligne contient un marqueur d'état accessible par le biais de la propriété RowState de l'objet Datarow.
La collection Datarows qui correspond aux lignes d'une table n'en reste pas moins une collection au sens DotNet. Donc lorsqu'on appelle la méthode Remove de la collection Datarows, on supprime le ligne de la collection, alors que lorsqu'on appelle la méthode Delete sur une ligne, on change sa propriété RowState en "Deleted" afin qu'elle soit supprimée du SGBD lors de la prochaine mise à jour. C'est seulement après cette mise à jour (en fait après l'appel AcceptChanges) que la ligne est aussi supprimée de la collection.
Donc pour résumé, la méthode Remove supprime la ligne de la collection Datarows sans influer sur les mises à jour suivantes tandis que Delete marque la ligne comme devant être supprimée lors de la prochaine mise à jour.
N.B : Dans la réalité, la méthode Remove supprime la ligne de la collection mais la ligne existe toujours étant marquée à l'état Detached.
|
| ||
| auteur : Jean-Marc Rabilloud | ||
C'est l'état qu'il y a entre le moment de la création de la ligne et de son ajout à une table, ou après son retrait de la table après appel de la méthode Remove. Prenons l'exemple suivant :
Cet état Detached est rarement utilisé hors quelques cas complexes.
|
| |||
| auteur : Jean-Marc Rabilloud | |||
Stricto sensu on ne peut pas, sauf dans le cadre de Linq to Dataset encore que ce soit une syntaxe particulière. On peut par contre par le biais de méthode de conteneur de données émuler certaines fonctionnalités des requêtes.
Utilisation de la méthode Select de l'objet Datatable. Celle-ci attend comme premier paramètre une chaîne de filtrage qui permet de récupérer un tableau de ligne correspondant au valeur du filtre.
Utilisation de la méthode RowFilter de l'objet Dataview qui fonctionne de manière similaire à la méthode Select mais en jouant sur la visibilité des lignes dans la vue.
L'ajout de colonne dites "d'expression" dans une table.
Voyons quelques exemples
Utilisation de Select.
Utilisation de RowFilter
Utilisation de colonnes d'expressions
Même si il est possible de créer des jeux de réponses relativement complexes avec ses méthodes, on est loin d'avoir la puissance d'un vrai langage de requête quand on travaille sur les Dataset. Il arrive forcément un moment où il faut se poser la question de gérer un code complexe plutôt que d'émettre une ou deux requêtes supplémentaires vers le SGBD.
|
| |||
| auteur : Jean-Marc Rabilloud | |||
La modification d'un Dataset valorise la propriété HasChanges mais ne génère pas d'évènement spécifique. Cependant il est possible de générer cette évènement par le code, en statique si vous utilisez un dataset généré ou en dynamique le cas non échéant comme dans l'exemple suivant :
Cet exemple est une approche immonde, normalement pour faire cela, on dérive un Dataset dans lequel on implémente la gestion de l'évènement. Par ailleurs, vous aurez une notification de changement même si la valeur n'a pas été modifiée. Il faudrait exercer un contrôle de modification sur les versions de ligne pour avoir une gestion correct.
Cela reviendrait à écrire un objet dérivé tel que :
Que l'on pourrait consommer comme dans :
|
| ||||||
| auteur : Jean-Marc Rabilloud | ||||||
Commençons par revenir rapidement sur les fondamentaux car la documentation des mises en relation est suffisamment trompeuse pour qu'on se mélange assez facilement. Fondamentalement, les difficultés tournent une fois de plus autour de la notion de schéma dans les Dataset. Pour comprendre cela, nous allons travailler avec trois tables de la base exemple Pubs, dont le schéma pourrait être représenté tel que :
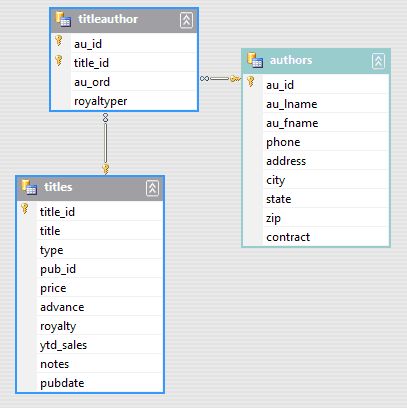
Nous allons construire le Dataset "From scratch" afin de bien comprendre le fonctionnement des relations. Contrairement à ce que la documentation peut laisser croire, les objets DataRelation ne sont pas liés aux contraintes. Autrement dit, on peut parfaitement construire au niveau d'un Dataset des relations sans que les tables contiennent des contraintes de clé primaire / clé étrangère ce qui diffère fondamentalement du fonctionnement des SGBD.
Prenons le code suivant :
Dans ce code, je vois bien que mes trois tables ne possèdent aucune contraintes (la boite de message affichera 0 0 0) mais que je peux mettre en relation mes trois tables puisque la grille va bien afficher les titres des livres ainsi que les nom et prénom de l'auteur.
Ceci veut dire que la seule création de la relation suffit à lire les informations connexes des tables mises en relation, en utilisant les expressions des DataColumn comme dans l'exemple précédent, ou bien les méthodes GetChildRows & GetParentRow de l'objet DataRow comme dans l'exemple suivant :
Pour le travail avec les relations c'est donc assez simple. Cependant il peut y avoir un problème à travailler de cette façon. Imaginons que dans le code nous ayons la ligne
et que nous envoyons les modifications vers le SGBD, nous allons obtenir une erreur de violation des contraintes d'intégrité. En effet, à la différence de notre Dataset, les relations du SGBD source sont gérées par des contraintes de clé étrangère qui dans le SGBD interdisent la suppression d'un enregistrement parent tant qu'il existe des enregistrements enfants.
Si nous voulons que le Dataset reproduise ce comportement afin d'anticiper les éventuelles anomalies, nous devons travailler avec les contraintes en plus des relations.
Supposons donc le code de création suivant pour notre Dataset :
La boite de message nous annonce bien la création de 4 contraintes (2 étrangères sur la table TitreAuteur et 2 primaires sur les tables parentes) et nous voila conforme.
La si nous utilisons la ligne :
Il ne se passera?..rien de plus.
Car par défaut, les contraintes créées par la méthode Add de la collection DataRelations sont réglés pour travailler en mode cascade. C'est-à-dire qu'en cas de suppression d'un enregistrement parent, les enregistrements enfants sont automatiquement supprimés aussi. Vous me direz que somme toute c'est un peu le but, mais cela n'est vrai que si l'on en est pleinement conscient, autrement cela veut dire que le Dataset agit à l'insu du développeur et que celui-ci devrait penser à se reconvertir comme dompteur d'huitre.
Pour avoir un comportement correcte, on doit donc soit laisser ainsi en sachant qu'on est en mode cascade, soit mettre la contrainte en mode 'pas d'action' soit par implémentation séparée de la contrainte, soit en écrivant :
Pour les survivants qui sont arrives jusque là sans aspirine, rappelez vous juste que dans un Dataset on peut gèrer séparément les relations et les contraintes.
N.B : Au cas où un petit malin pense qu'il suffirait de mapper le schéma de la source en appelant FillSchema, je rappelle que cette méthode ne mappe pas les contraintes de clés étrangères avec la majorité (tous ?) des fournisseurs.
|
Les sources présentées sur cette page sont libres de droits et vous pouvez les utiliser à votre convenance. Par contre, la page de présentation constitue une œuvre intellectuelle protégée par les droits d'auteur. Copyright © 2009 Developpez Developpez LLC. Tous droits réservés Developpez LLC. Aucune reproduction, même partielle, ne peut être faite de ce site ni de l'ensemble de son contenu : textes, documents et images sans l'autorisation expresse de Developpez LLC. Sinon vous encourez selon la loi jusqu'à trois ans de prison et jusqu'à 300 000 € de dommages et intérêts.
