
| ||
| auteur : Jean-Marc Rabilloud | ||
Dans ADO.NET, un fournisseur managé est un ensemble de classe permettant
l'interaction avec un SGBD spécifique. Microsoft donne comme schéma pour le
fournisseur :
 Fournisseur managé DotNet
Les fournisseurs managés contiennent généralement d'autres classes comme
CommandBuilder ou Transaction.
A l'installation, Visual Studio contient par défaut quatre fournisseurs managés :
Il en existe d'autres que l'on trouve généralement chez l'éditeur du SGBD comme Connector/Net 5.0 pour MySQL ou Borland Data Provider pour InterBase.
|
| ||
| auteur : Jean-Marc Rabilloud | ||
Cela revient à écrire un code permettant l'interaction avec plusieurs SGBD différents de la manière la plus concise possible.
En toute rigueur, si tous les SGBD avaient les mêmes fonctionnalités, il devrait être possible de faire un code fonctionnant pour tous les fournisseurs managés à la chaîne de connexion prêt. De fait, on en est assez loin. En pratique, tous les fournisseurs managés héritent des objets génériques de l'espace de nom System.Data.Common. Tant que le code reste sur les membres hérités, la généricité va être correcte, en dehors de cela il faudra implémenter les fonctionnalités à concurrence du modèle désiré ce qui peut être rapidement assez lourd.
Vous trouverez un exemple de base dans cet article de Didier Danse
| ||
lien :  Principes de réalisation d'un DAC indépendant du SGBD Principes de réalisation d'un DAC indépendant du SGBD |
| ||
| auteur : Jean-Marc Rabilloud | ||
La propriété FireInfoMessageEventOnUserErrors permet de traiter les exceptions comme des avertissements jusqu'à un certain niveau de gravité. Un avertissement (InfoMessage) est géré par un gestionnaire d'évènement spécifique mais ne bloque pas le code déclencheur comme dans le cas d'une exception.
Ceci implique que des modifications peuvent avoir lieu alors qu'une ou plusieurs ont échouées. Hors contexte transactionnel, cela ne pose pas de problème si la cohérence de ce fonctionnement a bien été envisagée. Dans le cadre d'une transaction, il est possible cependant qu'il y ait levée d'une exception InvalidOperationException lorsqu'il y a appel d'un RollBack sur une connexion en erreur. Pour contourner le problème, vous devez gérer un bloc Catch spécifique pour l'exception InvalidOperationException.
|
| |||
| auteur : Jean-Marc Rabilloud | |||
Utiliser une requête d'agrégation Count
Si vous utilisez un DataReader
Si vous utilisez un stockage dans un DataTable
|
| ||||
| auteur : Jean-Marc Rabilloud | ||||
Il s'agit d'un problème de performance / Maintenance. Prenons le cas de la propriété Ordinal pour des DataColumn, la problématique étant identique pour GetOrdinal. Imaginons un exemple classique de formulaire Maitre/Détails. Cet exemple ne pose évidemment pas de problème de performance mais la logique est la même.
Si ce code présente l'avantage d'être très lisible et donc facile à maintenir, il va avoir de mauvaise performance puisque chaque nom de champ devra être converti dans sa valeur numérique à chaque appel.
On pourrait évidemment écrire :
Ce qui conduirait à un code ayant de très bonnes performances. Cependant, outre la perte évidente de lisibilité, ce code est alors dépendant de l'ordre des champs dans la requête. Si le problème n'est pas très grave lorsque la requête est écrite dans le code (encore que?) cela peut être plus gênant lorsqu'on utilise une requête stockée dans le SGBD, surtout si on en n'est pas le rédacteur.
On trouve alors parfois un code qui tente de marier le meilleur des deux mondes en utilisant Ordinal tel que :
On conserve ainsi une bonne lisibilité tout en améliorant nettement les performances. Evidemment, lorsqu'il y a beaucoup de champs, l'affectation peut être un peu fastidieuse.
Notez qu'il existe une autre technique également utilisée reposant sur les énumérations telle que :
|
| ||
| auteur : Jean-Marc Rabilloud | ||
Lorsque le code doit contenir des requêtes SQL, il ne faut pas que celles-ci prennent en compte les saisies de l'utilisateur par concaténation.
Imaginons un formulaire contenant une grille ainsi qu'une zone de texte. En entrant le code de l'auteur on obtient la liste de ses livres ainsi que ses royalties.
Si on ne souhaite pas que quelqu'un puisse obtenir l'affichage de ces informations sans connaître le code de l'auteur, ce code n'est pas correctement sécurisé puisqu'il est sensible à une injection SQL. En l'état, si l'utilisateur entre dans la zone de texte la chaîne "' OR 1=1 -" il obtiendra l'affichage des informations pour tous les auteurs. C'est cette faille de sécurité qui déclenche l'avertissement ReviewSqlQueriesForSecurityVulnerabilities.
Pour ne pas avoir ce problème, on utilise plutôt une requête paramétrée telle que :
|
| ||
| auteur : Jean-Marc Rabilloud | ||
Il s'agit souvent d'un problème de conversion lorsque la valeur doit être NULL. En utilisant un contrôle de time DateTimePicker, on ne peut pas facilement entrer une valeur NULL dans le SGBD. On tend alors à utiliser un contrôle TextBox qu'on laisse vide pour gérer le NULL.
Prenons l'exemple suivant :
Si la zone de texte Ord_dateTextBox est vide, j'obtiendrais l'erreur de conversion. Il convient donc d'écrire :
|
| ||
| auteur : Jean-Marc Rabilloud | ||
Il n'existe pas de méthodes pour compacter une base Access sans utiliser un composant COM. Bien qu'il soit possible de le faire en faisant une référence à DAO, il est plutôt recommandé d'utiliser la bibliothèque Microsoft Jet and Replication Objects 2.x Library (JRO).
Ensuite de quoi il suffit d'écrire :
|
| ||
| auteur : Jean-Marc Rabilloud | ||
Il y a plusieurs méthodes de récupération selon la finalité envisagée, mais la plupart demande l'utilisation d'un flux intermédiaire. Tous les objets de données, Commande, DataReader ou DataRow permettent cette récupération. Dans l'exemple suivant, on affiche dans un PictureBox une image extraite à l'aide de la méthode ExecuteScalar de l'objet Command :
L'exemple suivant extrait toutes les images de la table sous forme de fichier à l'aide d'un DataReader :
|
| ||
| auteur : Jean-Marc Rabilloud | ||
Les définitions sont :
char[(n)]
Chaine de longueur n de caractères non unicode (1 < n < 8000). La taille sera de n octets
nchar[(n)]
Chaine de longueur n de caractères unicode (1 < n < 4000). La taille sera de n*2 octets
varchar[(n)]
Chaine de longueur variable de caractères non unicode. La valeur n maximale est de 8000. La taille réelle sera de 1 octet par caractère effectivement stockée. La chaîne stockée peut être de longueur nulle.
nvarchar[(n)]
Chaine de longueur variable de caractères unicode. La valeur n maximale est de 4000. La taille réelle sera de 2 octet par caractère effectivement stockée. La chaîne stockée peut être de longueur nulle.
|
| ||
| auteur : Jean-Marc Rabilloud | ||
Le moteur Jet d'Access tente toujours de convertir les dates entrées au format américain, c'est-à-dire MM/DD/YYYY. Lorsque vous entrez une date au format français, celle-ci sera converti au format américain si cela est possible (c.a.d. si le jour est inférieur à 13) ou correctement interprété si la conversion n'est pas possible. Vous devez donc employer des fonction de conversion ou de création de Date et non des littéraux. Par exemple :
|
| ||
| auteur : Jean-Marc Rabilloud | ||
C'est un peu le message d'erreur fourre tout. Il existe de nombreuses erreurs qui peuvent déclencher ce message, celui-ci étant principalement le signe d'une ambiguïté dans une commande ou du fonctionnement mal paramétré d'un objet de données.
On obtient par exemple ce message lorsqu'on tente d'insérer une valeur dans un champ auto incrémenté, lorsque la requête utilise un mot réservé, lorsque des éléments de la requête contiennent des espaces ou des accents, et ainsi de suite.
Dans la plupart des cas, l'erreur se situe au niveau de la requête et un examen de celle-ci suffit.
|
| |||||
| auteur : Jean-Marc Rabilloud | |||||
Nous sommes donc dans un mode déconnecté. C'est-à-dire qu'il n'y a pas de notion de position courante, dans l'absolu on peut même travailler sans connexion une fois les données chargées.
Pour identifier un enregistrement afin de faire des modifications, l'objet d'action utilisé va donc se servir de critère situé dans la requête d'action puisque c'est in fine de toute façon une commande qui va agir. Globalement il y a trois cas, pour ces commandes :
Nous allons travailler sur ce troisième cas puisque dans le cas de la gestion concurrentielle les problèmes sont toujours de même ordre quel que soit le cas choisis.
Prenons un exemple simple pour commencer en travaillant sur la table 'publishers' que l'on peut représenter comme :
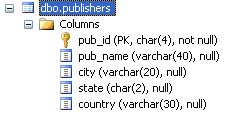
Commençons par une construction sans objet intégré, c'est-à-dire en ne travaillant qu'avec des commandes. Nous allons avoir un code de définition et de remplissage :
Un code créant des modifications :
Et un code appliquant ces modifications.
Détaillons un peu cela avant d'aller plus loin. Nous avons donc défini des requêtes paramétrées pour chaque type d'action, ajout, modification et suppression. Puis nous avons rempli la table des éditeurs. Dans le code de modification, nous avons ajouté un enregistrement, supprimé un enregistrement et modifié un.
Si la fonction de mise à jour peut paraître complexe, elle reprend le cheminement des objets "automatiques" intégrés dans le Framework comme le DataAdapter.
C'est-à-dire qu'elle extrait les lignes modifiées regroupées par type de modification, applique les paramètres en récupérant les valeurs dans la table et envoie les modifications vers le SGBD.
On pourrait donc écrire un code identique utilisant un DataAdapter tel que :
N.B : De fait, l'enregistrement qui doit être supprimé ne le sera que si les clés étrangères dans la base source liée aux éditeurs sont réglées sur cascade.
Mais revenons à notre sujet principal, la gestion de la concurrence. Les actions sont exécutées en respectant les requêtes. Dans notre exemple, l'insertion aura donc toujours lieu sauf si un enregistrement avec la même clé existe déjà, la suppression aura toujours lieu si l'enregistrement avec une clé identique existe et la modification aura toujours lieu si un enregistrement avec la clé existe. On appelle ce mode mise à jour sur clé, puisque seul le champ de la clé primaire est utilisé pour identifier l'enregistrement qui doit subir l'action.
Évidemment dans ce cas, nous n'aurons un problème de concurrence que si l'enregistrement ciblé a été supprimé entre le moment où nous avons rempli le Dataset et le moment de l'appel Update. Si l'enregistrement a été modifié par un autre utilisateur, nos modifications vont aller écraser les siennes sans qu'il y ait une levée de l'exception ConcurrencyException.
Pour éviter cela, on génère parfois un autre type de requête qui contient dans la clause WHERE la totalité des champs. Cela donnerait alors un code tel que :
Comme nous le voyons, il s'agit déjà de requête plus complexe nécessitant vite un grand nombre de paramètre. Vous noterez aussi qu'il faut gérer explicitement le cas des champs pouvant être Null. La chaîne de la clause WHERE contient tous les champs que l'on souhaite utiliser pour l'identification associés par des AND tel que :
Pour les champs ne pouvant pas être Null
NomChamp = @Original_param
Pour les champs pouvant être Null
((@Param_Null = 1 AND NomChamp IS NULL) OR (NomChamp = @Original_param))
Ce mode de contrôle sur tous les champs est parfois appelé mode "Optimiste pessimiste", puisqu'il ressemble à un verrouillage pessimiste dans le sens où tout enregistrement ayant été modifié par ailleurs ne pourra plus l'être lors de la mise à jour, il y aura levée de l'exception ConcurrencyException.
Il existe un troisième mode qui consiste à ne tester que les champs ayant été modifiés. Ce troisième mode est relativement complexe à mettre en place car il demande une génération automatique de la requête pour chaque ligne modifiée.
|
| |||||||
| auteur : Jean-Marc Rabilloud | |||||||
C'est la question à 3 $ des forums de développement, avec la réponse associée qui est du même tonneau, 'ça dépend' puisque cela dépend généralement du SGBD ciblé.
La problématique est généralement la suivante, dans un environnement de table en relation, on crée des enregistrements parents et des enregistrements fils et la clé primaire de la table parent est de type "auto-incrémentée". Cela veut dire que la valeur de la clé dans le Dataset à peu de chance d'être celle qui sera effectivement attribuée par le SGBD. Or cette valeur de clé doit être connue puisqu'elle sera la valeur dans la colonne de clé étrangère de la table fille et que la relation ne peut être correcte qu'à cette condition. Le problème se décompose donc en deux aspect, comment récupérer une valeur auto incrémentée attribuée par le SGBD et comment la propager dans les champs adéquats.
Pour réaliser ces actions, on pratique généralement selon le scénario suivant :
Prenons d'abord un exemple classique sur la base Northwind qui présente des tables en relation ayant des clés auto incrémentées que nous pourrions représenter telles que :
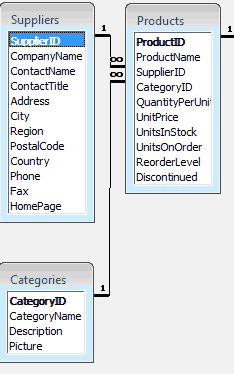
Commençons par manipuler une base Access, ce qui est un peu plus complexe puisqu'Access n'accepte ni les procédures stockée ni les lots de requêtes.
Je vais remplir le Dataset et utiliser des objets DataAdapter définis à minima pour pouvoir faire des insertions, le code de base pourrait être :
Le début du code est l'affectation classique de commande d'insertion dans les DataAdapter. On établit ensuite un identifiant local pour chaque table avant une clé primaire auto générée. Il existe plusieurs méthodes pour faire cela, mais la technique la plus couramment utilisée consiste à modifier les valeurs d'initialisation de l'auto incrément afin que les enregistrements ajoutés ne puissent avoir la même clé que les enregistrements existants. Il suffit pour cela de générer l'attribution d'un entier négatif ou nul, c'est ce que l'on fait avec le code :
N.B : Ce code doit être placé avant le remplissage de la table
Nous allons ensuite ajouter un fournisseur et un produit, celui-ci étant lié au nouveau fournisseur.
Expliquons la deuxième partie de ce code, puisque la première n'est que la valorisation et l'insertion des lignes dans les tables.
Les enregistrements ajoutés ont dans le Dataset une clé primaire dont la valeur a été attribué par le Dataset, c'est-à-dire négative ou nulle avec les règles que nous avons définis. Nous allons déclencher les mises à jour des tables. Cette mise à jour ne peut être faite que dans l'ordre parents -> filles sinon la mise à jour ne sera généralement pas possible (puisque le SGBD va corner si on tente de lui faire ajouter un enregistrement dont le père n'est pas défini. Nous allons abonner le DataAdapter à l'évènement RowUpdated afin de pouvoir récupérer et propager la valeur de clé générée par le SGBD.
Nous allons envoyer une copie filtrée de chaque table, celle-ci ne contenant que les lignes à insérer. Pour chaque ligne traiter, il y aura exécution d'un évènement RowUpdated que nous aurons codé sous la forme :
Que signifie ce traitement. Pour chaque ligne traitée, il va vérifier que nous sommes bien dans le cas d'un ajout d'enregistrement. Cet évènement se produit après l'envoi de la requête.
Dans Access, la requête SELECT @@IDENTITY renvoie la valeur du dernier numéro généré par le SGBD pour la connexion en cours. On récupère donc par l'exécution de la commande cmdNewID l'identifiant de l'enregistrement qui vient d'être inséré. A ce stade, il y a normalement appel de la méthode AcceptChanges dans une opération classique de mise à jour. Cet appel va entre autre modifier le statut de la ligne en "Unchanged" et envoyer les valeurs courantes vers les valeurs originales. Il faut à ce stade bloquer cet appel, ce que l'on fait à l'aide de la valeur de status 'SkipCurrentRow'.
Pourquoi ce blocage est-il indispensable ?
D'abord parce que pour réintégrer correctement la valeur généré par le SGBD, il va falloir fusionner la table d'origine et la table temporaire modifiée et que pour que cette fusion se passe correctement il faut que l'état de la ligne et la valeur originale dans la table modifiée soit identique à celle de la table d'origine. Ensuite parce qu'à ce moment, les enregistrements enfants possèdent encore comme clé étrangère la valeur initialement attribuée comme clé primaire par le Dataset. Nous devons donc propager la valeur d'identité récupérée vers les tables enfants. Pour cela, nous allons récupérer l'ensemble des lignes ayant comme clé étrangère l'ancienne valeur de clé pour affecter la nouvelle valeur de clé.
Ensuite de quoi nous pourrons fusionner les tables puis appeler 'AcceptChanges' pour finir de valider les modifications. On enverra ensuite la table enfant faire sa mise à jour selon le même principe.
Une approche un peu plus simple est possible avec des SGBD permettant d'envoyer des paramètres sortant et/ou des jeux de résultats multiples. Prenons un exemple sur la base Northwind pour SQL Server maintenant.
Le code de remplissage va être de la forme :
Ce qui est sensiblement identique sauf pour le paramétrage des DataAdapter ou nous allons ajouter :
La propriété UpdatedRowSource permet de définir comment les résultats d'une requête sont mappés sur la ligne de donnée. Dans ce cas nous préciserons qu'il s'agit de remplir la ligne avec les résultats renvoyés par la requête Select intégrée dans la mise à jour.
La propriété MissingSchemaAction permet de définir le comportement à adopter si des données récupérées ne cadre pas avec le schéma sortant.
Pour le reste c'est équivalent si ce n'est que la récupération de l'identité est gérée par le lot de requête et qu'il n'est plus besoin d'émettre une requête identité dans le gestionnaire d'évènement OnRowUpdated
|
| ||
| auteur : Jean-Marc Rabilloud | ||
Le chargement asynchrone consiste à récupérer les données sans interrompre l'exécution du programme principal. On s'en sert souvent lorsque le volume de données est important ou lorsque l'interface d'affichage fait que l'on peut raisonnablement penser que la récupération asynchrone ne sera pas préjudiciable. Il ne faut pas le confondre avec le chargement différé qui repose sur un autre principe, bien qu'il soit possible de faire les deux.
Le traitement asynchrone n'est pas particulièrement complexe à mettre en place. Il existe un traitement spécifique aux objets commandes avec le fournisseur managé pour SQL Server.
Commençons par celui-ci, c'est-à-dire l'exécution des méthodes BeginExecuteReader et EndExecuteReader.
Notons tout d'abord qu'il faut utiliser un délégué parce que nous utilisons dans cet exemple une surcharge utilisant une fonction de rappel. Il existe une autre surcharge qui ne passe pas par cette fonction. Vous devez utilisez au moins un délégué dans ce cas car seul le thread créateur des éléments de l'interface peut interagir avec celle-ci. Ceci implique que la fonction de rappel ne doit jamais directement agir sur l'interface d'où la nécessité du délégué.
Notez aussi que la chaine de connexion pour SQL Server doit contenir la paire clé/valeur ' Asynchronous Processing=true'
Notons enfin qu'il n'est pas possible d'intercepter une exception dans la fonction de rappel en utilisant l'UI sans délégué, d'où l'utilisation du journal d'erreur dans cet exemple.
Envisageons maintenant un cas plus général, avec une commande Access par exemple qui ne possède pas de méthode asynchrone BeginExecuteReader.
Dans ce cas, nous pouvons utiliser le composant BackgroundWorker qui permet de gérer assez simplement les traitements asynchrones. On obtiendrait alors un code tel que :
Notez que si le gestionnaire DoWork est soumis à la règle de non utilisation des éléments de l'interface, le gestionnaire ProgressChanged n'y est pas soumis.
|
Les sources présentées sur cette page sont libres de droits et vous pouvez les utiliser à votre convenance. Par contre, la page de présentation constitue une œuvre intellectuelle protégée par les droits d'auteur. Copyright © 2009 Developpez Developpez LLC. Tous droits réservés Developpez LLC. Aucune reproduction, même partielle, ne peut être faite de ce site ni de l'ensemble de son contenu : textes, documents et images sans l'autorisation expresse de Developpez LLC. Sinon vous encourez selon la loi jusqu'à trois ans de prison et jusqu'à 300 000 € de dommages et intérêts.
